Are you tired of robotic sounding text-to-speech applications? Well, Microsoft has some exciting news for you! They have just announced VALL-E, an AI model that can closely mimic a person’s voice with only a three-second audio sample. This technology not only replicates the sound of a person’s voice but also attempts to preserve the speaker’s emotional tone.
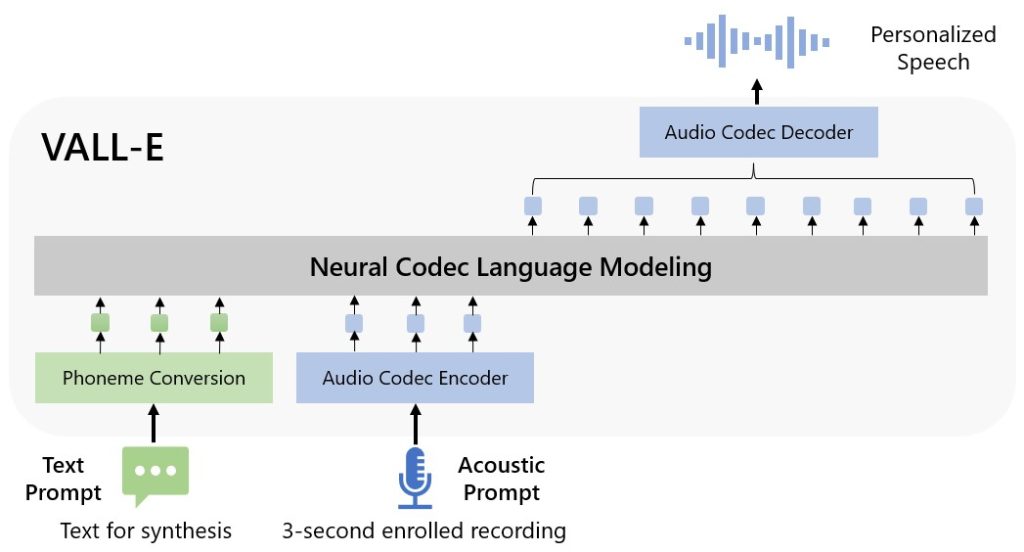
The possibilities for VALL-E are endless, from high-quality text-to-speech applications to speech editing and audio content creation when paired with other AI models like GPT-3 and ChatGPT. Microsoft has classified VALL-E as a “neural codec language model” and it is based on a technology called EnCodec, which was announced by Meta in October 2022.
Unlike traditional text-to-speech methods that rely on waveform manipulation, VALL-E generates discrete audio codec codes from text and acoustic prompts. It analyzes the way a person sounds, breaks that information into discrete components, and uses training data to match how that voice would sound if it spoke other phrases beyond the three-second sample.
The results of this revolutionary technology are mixed, with some samples sounding machine-like and others being almost indistinguishable from a real human voice. You can listen to the samples yourself on the VALL-E research page: https://valle-demo.github.io/. The fact that it preserves the emotional tone of the original samples is what sets it apart from previous text-to-speech models. VALL-E also accurately matches the acoustic environment, meaning if the speaker recorded their voice in an echo-y hall, the VALL-E output will also sound like it came from the same place.
Microsoft plans to continue improving the model by scaling up its training data and finding ways to reduce unclear or missed words. While VALL-E does pose a threat to voice actors and narrators, it also offers a new level of personalization and connection for people who want to keep the memory of a loved one’s voice alive. The Microsoft VALL-E team has added an ethics statement on their demonstration page, acknowledging the potential implications of this technology when applied to unseen speakers. They stress the importance of ensuring the speaker agrees to any modifications and having systems in place to detect edited speech.
The world of AI is constantly advancing, and VALL-E is just the latest example of how technology can bridge the gap between the past and the present. It offers a new level of text-to-speech that was previously impossible. We can’t wait to see how it will advance and be used in the future!

