
Bloomberg has introduced a new large-scale AI model, BloombergGPTTM, a large language model specifically trained on a wide range of financial data to support a diverse set of natural language processing tasks within the financial industry. This new model represents a major step in the development and application of this new technology for the financial industry.
The Development of BloombergGPT
Bloomberg’s ML Product and Research group worked closely with the firm’s AI Engineering team to construct one of the largest domain-specific datasets yet, drawing on the company’s existing data creation, collection, and curation resources. The team pulled from this extensive archive of financial data to create a comprehensive 363 billion token dataset consisting of English financial documents. This data was augmented with a 345 billion token public dataset to create a large training corpus with over 700 billion tokens. Using a portion of this training corpus, the team trained a 50-billion parameter decoder-only causal language model.
Performance of BloombergGPT
BloombergGPT outperforms existing open models of a similar size on financial NLP tasks by significant margins, while still performing on par or better on general LLM benchmarks. The model has been validated on existing finance-specific NLP benchmarks, a suite of Bloomberg internal benchmarks, and broad categories of general-purpose NLP tasks from popular benchmarks.
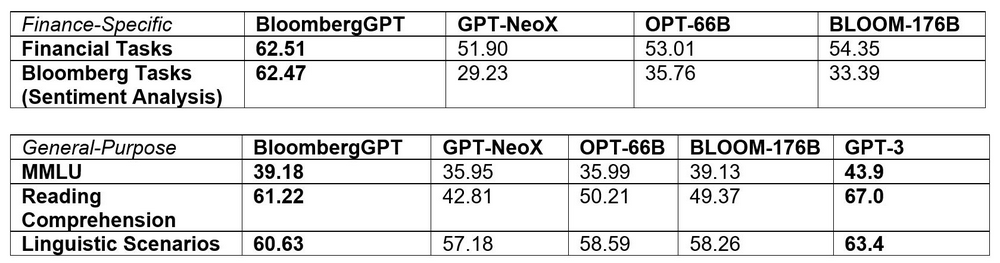
Advantages of BloombergGPT
The development of BloombergGPT represents a significant milestone in the application of AI, Machine Learning, and NLP in the finance sector. BloombergGPT enables the firm to tackle many new types of applications while delivering much higher performance out-of-the-box than custom models for each application, at a faster time-to-market.
BloombergGPT Resources
If you’d like to learn more about the research and development of BloombergGPT, there are several resources available. First, the original paper, titled “BloombergGPT: A Large Language Model for Finance,” was published on arXiv, an open-access resource for research articles and papers, by Cornell University. You can also read Bloomberg’s official press post with more technical information and comparison data: https://www.bloomberg.com/company/press/bloomberggpt-50-billion-parameter-llm-tuned-finance/

